It’s been a while I wrote a technical article in this blog. I was busy in too many things and didn’t get a chance to focus on this website. Saying that, I had a steep learning curve in Azure cloud & it’s related technologies. I’m happy that I wrote this article and got a chance to share it. Going forward I hope I can share my experiences and learnings.
Let me explain what I was trying to do with data bricks workspace. Our data bricks workspace is part of a VNET and a couple of subnets within the VNET as shown below.
Existing Network Configuration
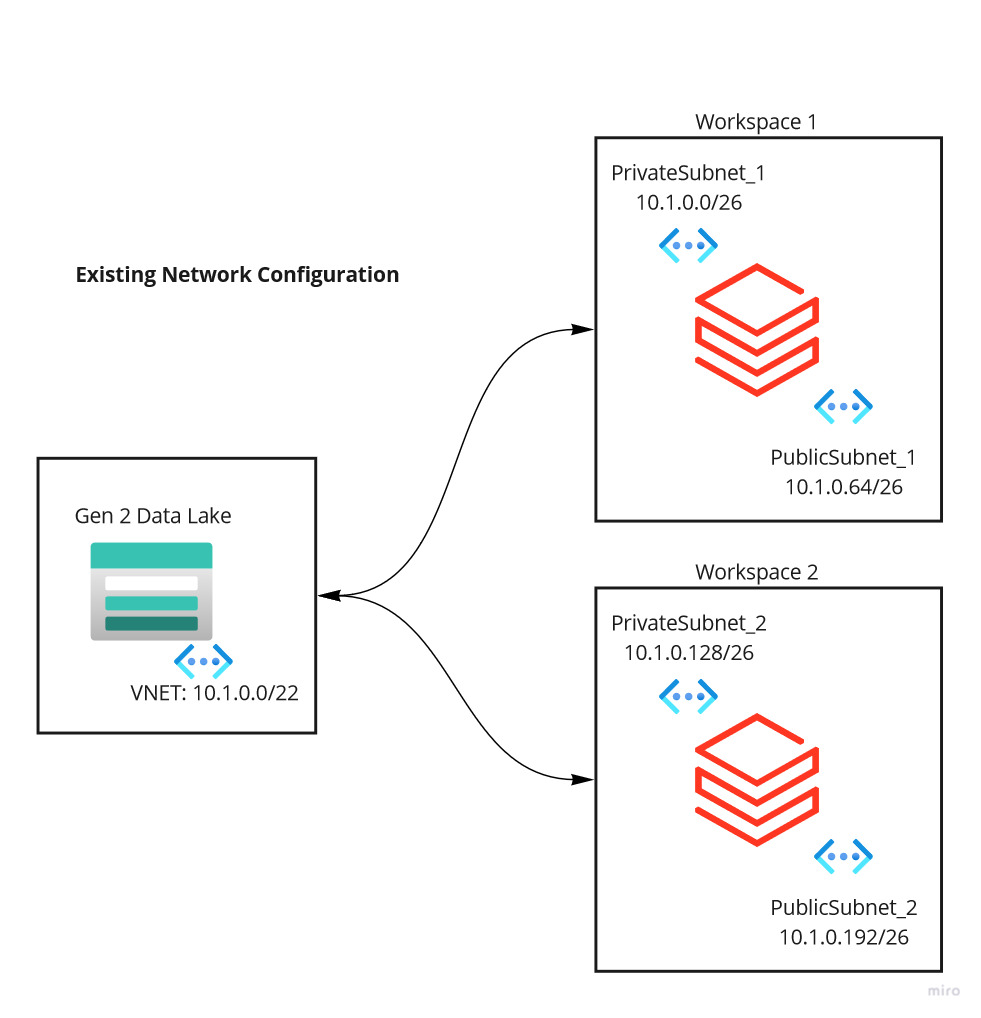
| Description | CIDR | Total IP Address | Usage |
|---|---|---|---|
| VNET | 10.1.0.0/22 | 1024 | DB Workspace |
| PrivateSubnet_1 | 10.1.0.0/26 | 64 | Workspace 1 |
| PublicSubnet_1 | 10.1.0.64/26 | 64 | Workspace 1 |
| PrivateSubnet_2 | 10.1.0.128/26 | 64 | Workspace 2 |
| PublicSubnet_2 | 10.1.0.192/26 | 64 | Workspace 2 |
The problem here is that for workspace 1 and 2 only 64 IP addresses are allocated. In which 5 will be reserved for internal usage and only 57 IP spaces are allowed to use per subnet. This directly relates to the underlying clusters provisioned by the workspace which means we can only provision up to 57 nodes/clusters for that workspace.
Don’t ask me why this was set up to 64 initially? This was set up a while ago and let’s not step into that.
Now we are in a situation where workspace 1 is quite extensively used with large data sets and requires more nodes to process the data quickly. Since we are tied up directly to the number of IP ranges in the attached subnet, we cannot exceed more than 57 nodes. When data bricks cluster tries to scale up it will end up with an error message saying not enough IP addresses exists.
This is where we wanted to expand the number of IP’s in private and public subnets 1. We cannot expand the subnet as the sequence range is already assigned to private and public subnet 2 for workspace 2. I was thinking to do below changes to the subnet so that we can expand subnets 1.
At the time of writing this article, based on the KB article suggests changing VNET is not possible without recreating the workspace however there are no details around changing CIDR, so I assumed I can do changes to underlying subnets. Since the subnets are part of the same VNET, it uses the same NSG and the firewall rules are not changed. Necessary access is granted to the service endpoints for all the subnets through the NSG.
I wanted to change as below. If you notice I wanted the IP range 10.1.0.x (256 IP Address space) to be solely used by workspace 1 and 10.1.1.x will be assigned to workspace 2.
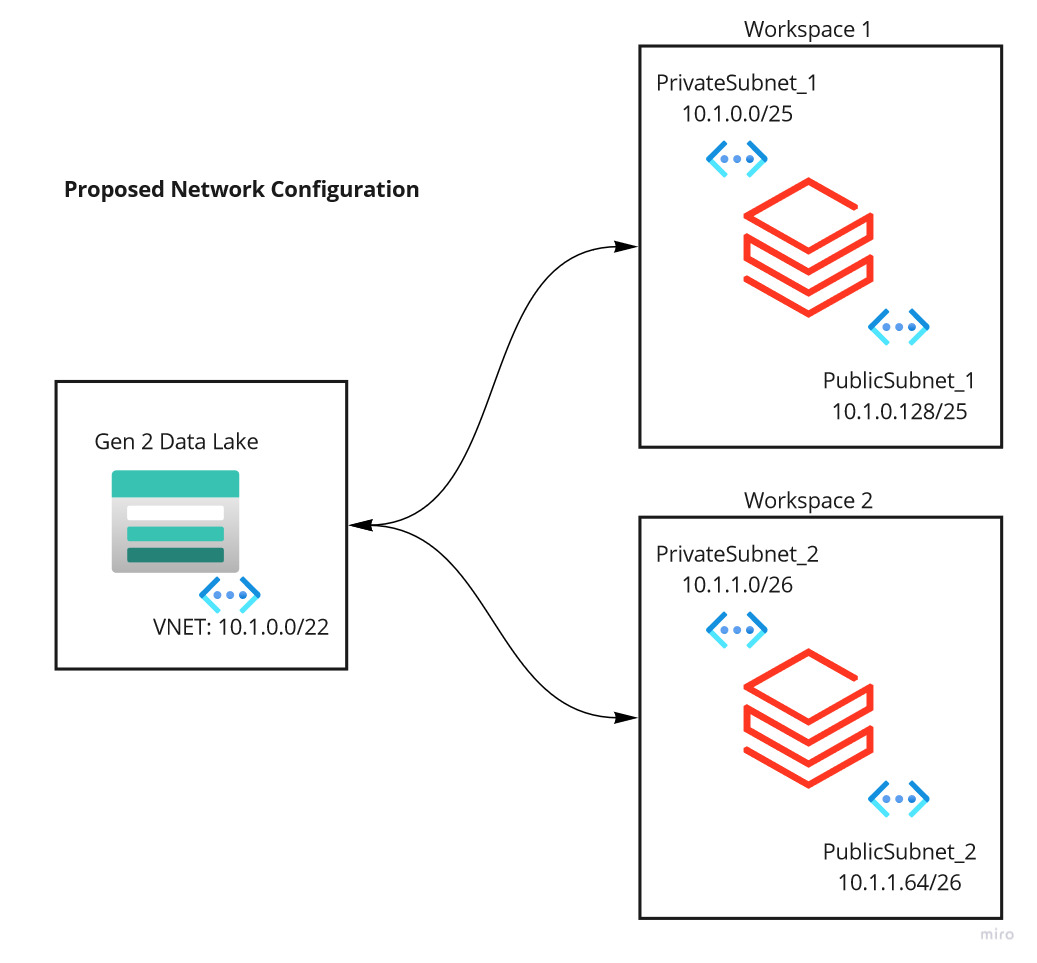
| Description | CIDR | Total IP Address | Usage |
|---|---|---|---|
| VNET | 10.1.0.0/22 | 1024 | DB Workspace |
| PrivateSubnet_1 | 10.1.0.0/25 | 64 | Workspace 1 |
| PublicSubnet_1 | 10.1.0.128/25 | 64 | Workspace 1 |
| PrivateSubnet_2 | 10.1.1.0/26 | 64 | Workspace 2 |
| PublicSubnet_2 | 10.1.1.64/26 | 64 | Workspace 2 |
I started with workspace 2 as workspace 1 is critical, and I want to avoid taking a chance. I moved workspace 2 to the proposed IP range successfully however I ended up with another issue. Cluster started successfully, I could run queries using notebook. Listing files and folders in the mounted data lake storage works perfectly fine. When the data is read(even a small data set), it never completed, and it was running forever. Upon investigating further I don’t see any errors in the cluster logs however I could see the below warning continuously written to the logs.
WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resourcesUpdate 1
I saw this warning before when the slave is not ready to accept the jobs. This led me to the assumption that for some reason the control plane is unable to communicate to the data plane. I suspected that the NSG created internally by Microsoft in the managed resource group might be the problem. To validate this further, I picked up one of the slave node and tried pinging it from the notebook (which gets initiates from the master node), below is the query to ping slave node from master node through notebook. As expected, there isn’t any connectivity to the slave nodes. This proves that the control plane is unable to communicate to the data plane.
%sh ping -c 5 10.1.1.33
I rolled back the subnet changes to workspace 2. After this, I could read the data correctly from data lake using data bricks notebook.
This is where, I thought, might be changing CIDR for the underlying subnet is not supported, and probably I have to recreate the workspace.
Update 2
I raised a case with Microsoft support to get to know whether this is possible. Simultaneously, I have also tested extending CIDR for workspace 1 within the same IP range instead of spilling to the next range. For instance, I completed the proposed changes, as expected, workspace 2 is unable to read data from data lake. However, workspace 1 is working fine and could read the data. The only difference in workspace 1 is that it remains in the same IP range, say, 10.1.0.x whereas workspace 2 is moved from 10.1.0.x to 10.1.1.x.
Meanwhile, I got a response from the support saying that this isn’t possible as the CIDR details is stored within the data plane at the time when workspace is provisioned. A change to underlying subnet CIDR will not update the network configuration data within the data plane and that’s causing the control plane unable to communicate to the data plane. Now everything makes sense to me, the solution given by Microsoft is to recreate a new workspace and migrate everything to the new workspace.
The solution seems to be simple however it’s a hard one for us as the workspace is customized a lot including the configurations, permissions and settings. This is going to take a while for us to migrate to the new workspace.
I have also raised with the support that I could extend the CIDR within the same IP range and that was working fine. Since this is working, I wanted to know is there any other issue we might expect or this is not an expected scenario at all.
Conclusion
To summarize, VNET and Subnet changes are not possible once the data bricks workspace is provisioned as the CIDR details are stored in the data plane, and it won’t get updated when underlying subnet CIDR is changed. The correct way of doing the change is to recreate another workspace and migrate everything to the new workspace.
Leave a Reply